3.Pandas常见函数与数据处理
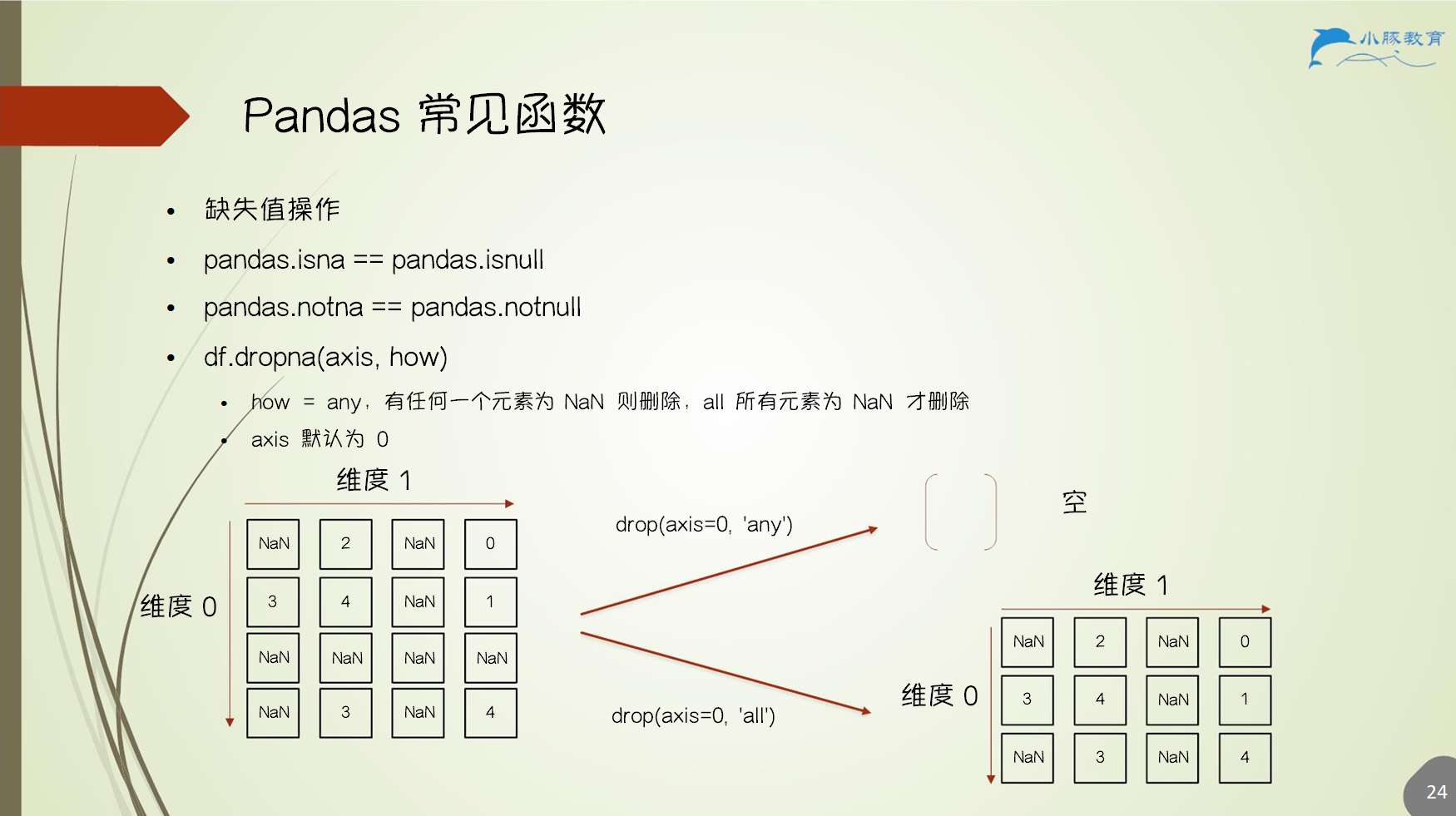
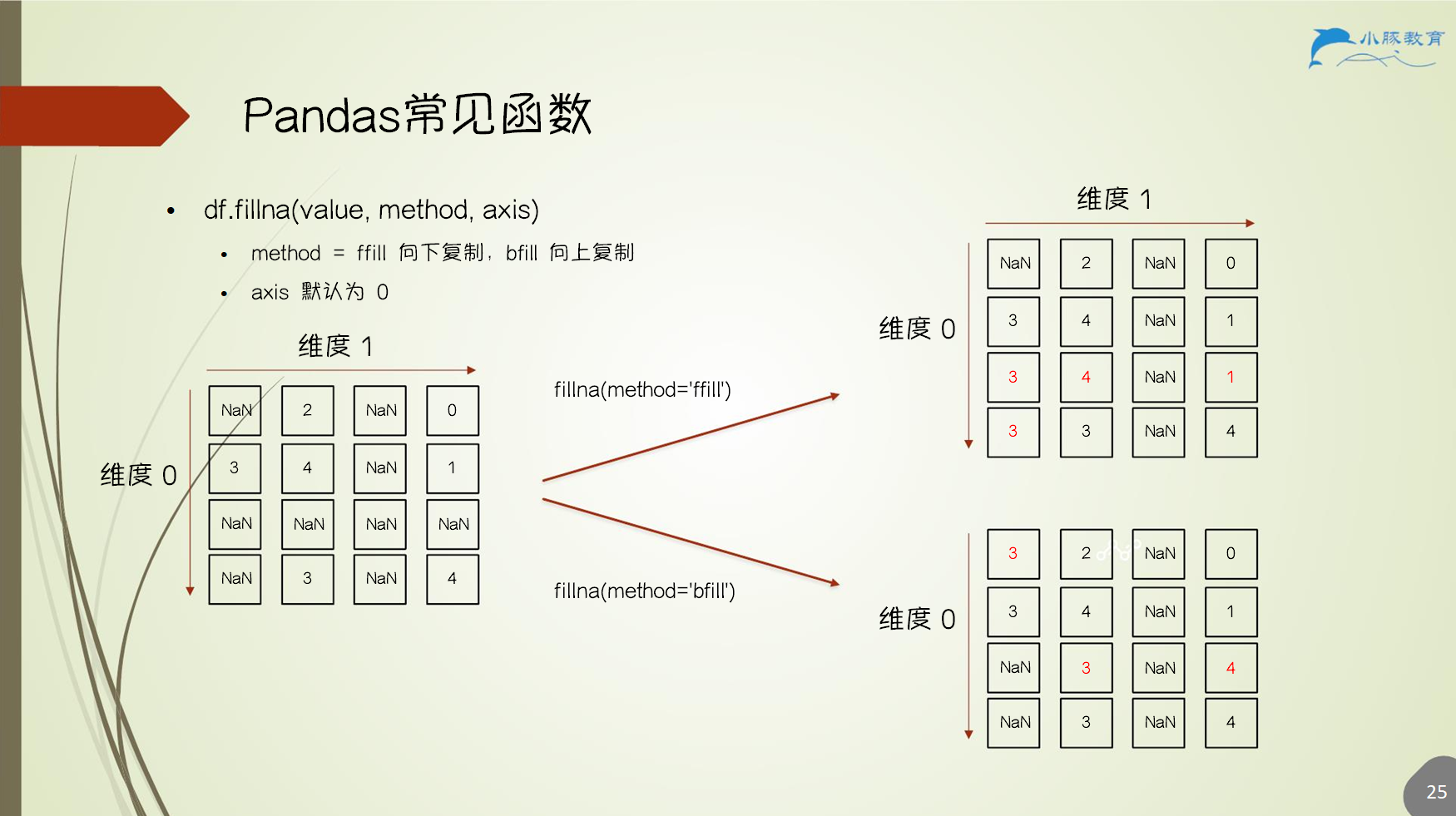
3.1 缺失值操作
3.2 赋值操作
赋值操作
df.loc[] = valuesdf.loc[] = df.apply(func, axis)df.apply返回Series
df.loc[] = df.applymap(func)- 针对
DataFrame每个元素进行函数操作
- 针对
df.assign(col_name=func)- 返回新的包含更新的
col_name的DataFrame
- 返回新的包含更新的
- 尽量使用
df.loc[],避免使用df[]赋值
SettingWithCopyWarning- 尝试修改一个从
DataFrame选择出来的引用对象view df[condition][column] = valuesdf.loc[condition, column] = values
- 尝试修改一个从
3.3 统计函数
df.describe()df.info()df.min()df.max()df.mean()df.value_counts()- 统计每一行元素数据出现的次数
- 将列变为
index - 生成
Series
df.corr(): 数值列之间的皮尔逊相关系数df.cov():数值列之间的协方差
3.4 排序
sort_index(axis, level)sort_values(by, ascending)- 依据哪些维度进行升序或降序排序
by可以是多个列,ascending对应每一列升降,不同列可以指定不同的顺序- 类比 SQL 的
order by col1 asc, col2 desc
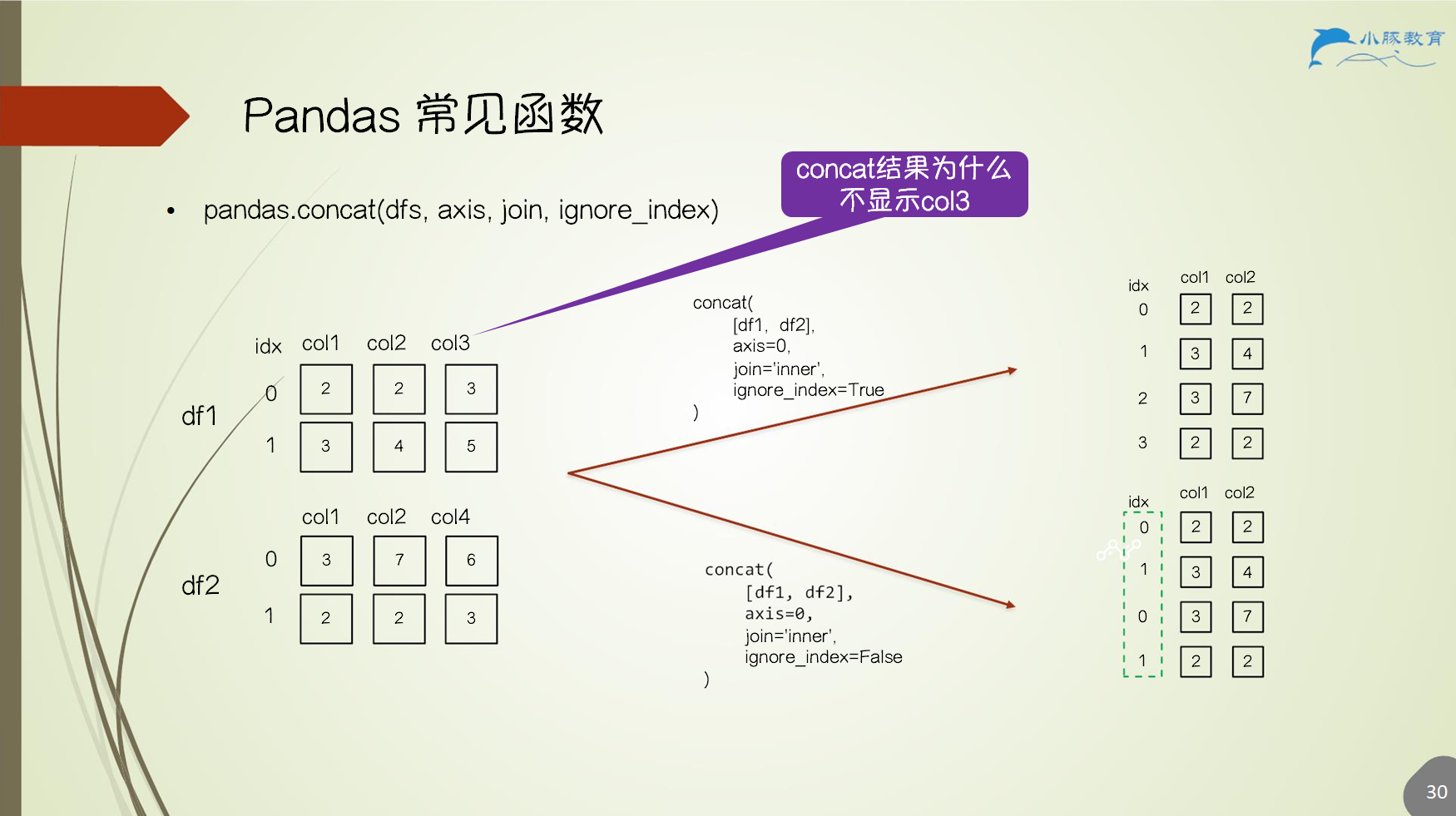
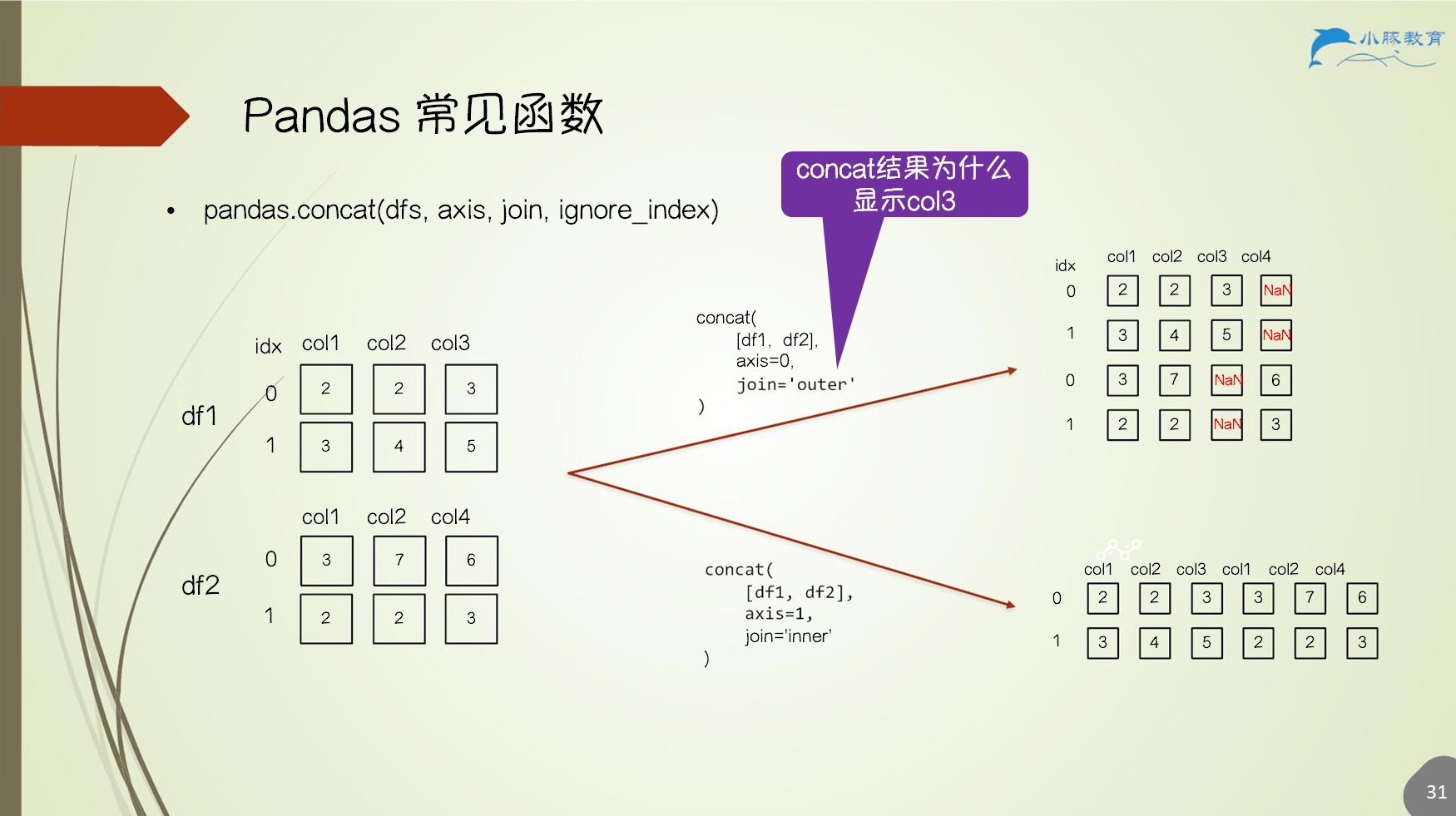
3.5 数据合并
pandas.concat(dfs, axis, join, ignore_index)- 一般用做数据点拼接,行方向数据拼接
- 列拼接时需要
index对齐 join默认outer join,inner/outerignore_indexTrue重设 index0, …, k,否则按照原 index 拼接
pandas.append(将废弃)- 按行方向的 concat,等价于
concat(axis=0)
- 按行方向的 concat,等价于
pandas.merge- 一般用做特征拼接,列方向拼接
3.5.1 concat 函数
3.5.2 merge 函数
pandas.merge( left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, suffixes=('_x','_y') )left,right,两个需要拼接的 DataFrame 或 Serieshow,以何种方式拼接,left/right/outer/inner/crosson,以哪一列为基准对齐拼接,需 left 和 right 均包含该列left_on,right_on,左侧 DataFrame 以left_on为基,右侧以right_on为基left_index,right_index,左侧 DataFrame 以left_index为基,右侧以right_index为基left_index可与right_on配对,反之亦然suffixes,若 DataFrame 重名,则添加后缀
3.6 groupby 函数
df.groupby(列名)- 返回
pandas.core.groupby.generic.DataFrameGroupBy - 可遍历得到每组 DataFrame,
for key, group_df in df.groupby()- 其中
key为分组值,group_df为分组值对应数据
- 其中
- 可聚合统计
- 可多个列同时分组
- 可以对
DataFrameGroupBy进行取值操作df.groupby()[列名]
- 返回
agg(func[s]) == aggregate(func[s])- 聚合
DataFrameGroupBy对象 - 若是 DataFrame 则聚合全部数据
- 类比 sql
sum等聚合函数 - 若多个聚合函数,列索引将多一级聚合函数的索引
- 聚合
3.7 inplace 参数
- 修改原
DataFrame还是生成新DataFrame - Pandas 基本所有数据操作都可以在原
DataFrame上修改数据 - 默认
inplace=False,需明确inplace=True以修改原数据
3.8 Pandas 数据处理案例
案例:100 个日报 csv 文件合并,见 notebook